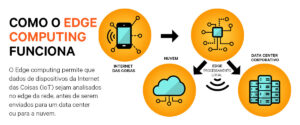
Toda inteligência artificial generativa atual tem o potencial de alucinar, sendo esse um dos principais problemas da tecnologia. O Google, em uma tentativa de minimizar o problema, criou o DataGemma, uma IA capaz de corrigir a própria IA.
Anunciada nesta quinta-feira (12), a ferramenta é composta por modelos treinados exclusivamente em dados contidos no Data Commons, banco de dados aberto mantida pelo Google. Porém, diferente do conteúdo em circulação na internet, as informações da plataforma são ancoradas em sites de instituições reconhecidas.
O DataGemma atua sobre as respostas do modelo do Google de duas formas: RIG (Retrieval-Interleaved Generation) e RAG (Retrieval-Augmented Generation).
 O Google criou uma IA para corrigir erros e alucinações da própria IA.Fonte: GettyImages
O Google criou uma IA para corrigir erros e alucinações da própria IA.Fonte: GettyImages
No primeiro método, o RIG, o DataGemma gera um “rascunho” da resposta e depois confronta o resultado com conteúdo presente no Data Commons, corrigindo tudo que pode ser ajustado com base de dados pública.
Já no RAG, é o caminho oposto: primeiro, o modelo confere se a resposta da pergunta do usuário está contida no Data Commons, gerando uma resposta a partir desses dados. Essa alternativa reduz a possibilidade de alucinações, segundo o Google.
“Nosso objetivo é usar o Data Commons para aprimorar o raciocínio dos LLMs (grandes modelos de linguagem) ao lastreá-los com dados estatísticos do mundo real que podem ter origem rastreada”, pontuou o diretor do Data Commons no Google, Prem Ramaswami. O resultado disso é uma IA “mais confiável”, segundo ele.
Atualmente, o DataGemma está disponível exclusivamente para pesquisadores, e existe a possibilidade de o acesso ser ampliado futuramente. Se tudo der certo, a solução pode ser crucial para a implementação de modelos generativos no buscador do Google.
Solução também tem defeitos
Obviamente, o DataGemma não é impecável. O primeiro problema dessa solução é a limitação de dados do Data Commons — se a informação não estiver contida na plataforma, não tem como o modelo verificar sua veracidade. Infelizmente, isso acontece em uma infinidade de cenários.
A ferramenta poderia verificar a consistência de dados científicos, como dados econômicos de um determinado país, mas não poderia garantir que a data de lançamento do último hit de Taylor Swift está correta.
Segundo o Google, o DataGemma não conseguiu extrair informações relevantes em 75% dos casos experimentais. Além disso, mesmo com se o conteúdo existe na base de dados, o modelo não conseguiu alcançá-los para formular uma resposta correta.
Além disso, o DataGemma também erra. Os pesquisadores perceberam que o modelo entregou respostas erradas entre 6% e 20% das tentativas ao utilizar o método RAG. O RIG, por sua vez, foi mais eficiente, permitindo que a IA extraísse dados 58% das ocasiões.
O princípio do DataGemma é o mesmo de modelos generativos comerciais: quanto maior a base de dados disponível, mais preciso tende a ser a IA. Portanto, com a ampliação do treinamento e refinamentos no modelo, a ferramenta tende a ficar mais precisa e eficiente para corrigir respostas.
De toda forma, a solução ainda está longe de ser perfeita e não resolve o problema das alucinações de IAs generativas, mostrando, mais uma vez, que os chatbots não estão certos 100% do tempo.